Our Heuristics are Shaped Through Experience
This post is part two of some reflections on a conversation I had with Chelsea Troy about our testing heuristics. You may also want to read part one and Chelsea's writeup.
I shared with Chelsea how my Smalltalk development background contributed to my testing and design heuristics. I was involved in the early days of Smalltalk at Tektronix as a principal engineer in the AI Machines group. After a yearlong stint managing the software group through product introduction, I switched back to full-time engineering. Among other things, I added features to Smalltalk including color graphics, fonts, and support for low-level OS calls. All our code was visible to our users, and we had a strong engineering culture.
I learned how to work effectively in the Smalltalk environment by studying existing code, figuring out what it did, and understanding its coding and design style. I also observed more experienced Smalltalk programmers. Kent Beck, along with Ward Cunningham, and other Tek Lab’s folks were some of the very earliest Smalltalk application programmers. Ward and Kent worked together, developing prototypes and exploring what Smalltalk was good at. Many ideas about Extreme Programming (and TDD) and object-design can be traced back to these programming experiences.
The Smalltalk image was always running. It contained the entire development environment and had a browser where you could look at existing code and add your own. Much of my time was spent experimenting with and reading existing code, then trying to fit my new code in. The code I wrote was a mix of new classes as well as extensions or modifications to existing ones. To show someone else how to use your code, you’d create a workspace—a scratchpad window—and put snippets of commented code for them to read, edit, and evaluate it. By convention, methods were categorized (see the third pane of the System Browser below, which shows the categories for the abstract Collection class). Other classes also had a testing category, but it was not used for what you might think! The testing category for the class Collection included methods for querying (i.e. testing) its contents.
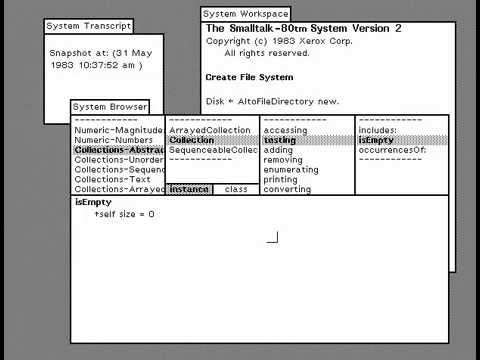
So how did programmers test Smalltalk code? I didn’t have any conventions to follow for organizing my tests (and not inconsequentially, leaving test code around would clutter up the Smalltalk image). Since I could highlight code anywhere and execute it, I tested code as I wrote it. I could step through code with a debugger, change it on the fly, and run it again. I tested my code into existence, but didn’t leave around any tests.
In an article I wrote about Color Smalltalk here’s how I described this experience: “… the workspace, lets programmers experiment with code without actually incorporating the experimental code into the valid, running environment. A programmer can write, execute and debug code in a workspace, then pull it into the Smalltalk application when the new code is tested and operational.”
While this statement is mostly true, it is also misleading. Anything I did as a programmer would add more objects to and change the state of the running Smalltalk image. Code you executed in a workspace changed the image (sometimes with catastrophic results, especially if you were tinkering with basic low-level system functionality as I was). But the Smalltalk environment and tools made it so easy to back up a step or two, revise your code, and try again, even with code that mucked with low-level stuff.
Kent’s Smalltalk experience heavily influenced how he thought about incremental development. But when it came to testing, I suspect he tried to boil down his Smalltalk experiences into practices that would be more “failsafe” for programmers who didn’t work in such a dynamic and forgiving development environment. Kent’s thinking about testing has evolved since he wrote his books. In an interview with Andrew Binstock in 2019, Kent and Andrew chat about this evolution:
Binstock: Do you still work on strictly a test-first basis?
Beck: No. Sometimes, yes.
Binstock: OK. Tell me how your thoughts have evolved on that. When I look at your book Extreme Programming Explained, there seems to be very little wiggle room in terms of that. Has your view changed?
Beck: Sure. So there’s a variable that I didn’t know existed at that time, which is really important for the trade-off about when automated testing is valuable. It is the half-life of the line of code. If you’re in exploration mode and you’re just trying to figure out what a program might do and most of your experiments are going to be failures and be deleted in a matter of hours or perhaps days, then most of the benefits of TDD don’t kick in, and it slows down the experimentation—a latency between “I wonder” and “I see.” You want that time to be as short as possible. If tests help you make that time shorter, fine, but often, they make the latency longer, and if the latency matters and the half-life of the line of code is short, then you shouldn’t write tests.
Binstock: Indeed, when exploring, if I run into errors, I may backtrack and write some tests just to get the code going where I think it’s supposed to go.
Beck: I learned there are lots of forms of feedback. Tests are just one form of feedback, and there are some really good things about them, but depending on the situation you’re in, there can also be some very substantial costs. Then you have to decide, is this one of these cases where the trade-off tips one way or the other? People want the rule, the one absolute rule, but that’s just sloppy thinking as far as I’m concerned.
Practicing TDD ensures developers write tests. The underlying value heuristic is, “any tests are better than no tests.” But if we take Kent’s more recent thoughts to heart, we shouldn’t test without thinking through some consequences. Kent’s more recent guiding heuristic: Test when it matters and when you need a safety net. Think through both the benefits and costs of testing. If you are exploring, don’t let testing slow you down.
There is no single “definitive” answer to the question, “when should I test?”
Develop Test Strategies Based on System Context #
Chelsea asked, “So, how do you determine what kinds of tests to write?”
I don’t have a definitive answer to this question, either. So, I shared a few stories. I’ve worked with clients unschooled in TDD. They write code, test it a little, and then throw these initial tests away. They build successful products. The tests they tend to keep are regression tests, tests that demonstrate a quirky bug that has been fixed (and to ensure that it stays that way). It’s always a bet.
If code is stable, and the tests always pass, running tests all the time isn’t buying any new information. Even worse, passing tests can give you a false sense of security about your code’s quality. So why do we write tests?
I like to focus on writing tests that check that stable (relatively unchanging) system expectations still hold, and that demonstrate ways new capabilities can be safely added. I also try to write tests that capture expectations I have around my system’s behavior.
For complex systems, though, this can be difficult. Unforeseen side effects can pop up in strange places (changing code in one place unexpectedly causing other code to break in a distant part of the system). It’s impossible to test for every possible edge case and you don’t know all the dependencies.
I remember Kent Beck telling this oddball story of writing his first TDD code when he went to work at Facebook. His code, which passed all his tests, suddenly caused other tests for other parts of the system to fail. Rather than revert his code, those familiar with the system decided to throw out those failing tests. Seems weird, but they knew those tests were brittle, and making some wrong assumptions. When you find problems with tests, think carefully about whether it is appropriate to add additional tests to ensure that things don’t break, whether your existing tests are brittle, or whether your assumptions are wrong.
Data Scientists Have Different Testing Values #
When you need to process massive amounts of data, and the code for processing of that data is predictable, there is little value in repeatedly running functional tests that always pass.
I worked for a number of years for a client doing healthcare analytics on patient medical data. Sometimes, their heuristic for verifying an algorithm would be: test that the new code works by comparing its results against code written in an entirely different system/programming language. They would take a massive cut of the data and run it through and compare the results.
Another heuristic they sometimes used to test new algorithms and capabilities was to run their code and compare their results against those reported in published research papers. Where the results differed, they need to reason about those differences (sometimes it was a problem with their code; at other times, it was that their code was more accurate at choosing cohorts or their statistical algorithms were better). Some person needed to critically analyze the results, reason why the discrepancies were there, and determine what, if anything, to do about them. This process couldn’t be automated.
Chelsea works with data scientists at Mozilla on sanitizing personal data for searches. The rules for this are complicated, language-specific, and sometimes people enter search terms in more than one language. She finds data scientists don’t share the same testing values as many software developers do.
Data scientists make informed assumptions about aggregated data. If those assumptions don’t hold, they reassess the data processing rules and revisit their assumptions. To them, testing is insufficient to ensure system quality. Monitoring actual system behavior against expected data characteristics, however, is critical. When the data characteristics being monitored fall outside of expected tolerances, this triggers developers to look into the situation. Developers then run some automated tests to determine if something is wrong with their code. If those automated tests pass, they then call on a data scientist to analyze a sample of the data and decide what to do. Something has changed and there likely needs to be some change to either in the assertions about the data’s characteristics or the rules for handling it.
Trialing new Heuristics #
Chelsea and I appreciate what we can learn from people with different backgrounds: data scientists, QA folks, testers, and new colleagues. There are many different ways to test and design software. And if I don’t hold onto my preferred heuristics too tightly, I might learn something.
But how do I decide when to try out some new heuristics or to stick with what I know?
If things are going well, I’m not as motivated to try out new ideas. I need a small nudge. I’ll try new some new-to-me heuristics if I feel I have some wiggle room. Let me experiment, practice, and think through the consequences. Give me a bit of time to let new values and practices soak in.
When I start to work on a new system or folks from different backgrounds, that too, is another opportunity to try out new ways of working.
But under pressure, I find myself narrowing my focus and sticking with what I know best (even if it is a poor option). So, if I can, I catch myself and take a small step back from problem solving. I pause, take a breath, and ask: If my heuristics aren’t currently working for me, what are some options?
If I want to introduce a test-first TDDer to my testing approach, I might suggest a modest experiment: “Let’s work together on some design and coding problems and compare our two approaches. Let’s find out what tests we come up with following my test-driven development approach. Let’s try your test-first TDD on a similar problem and see what tests we come up with. Let’s see what we learn.”
At the very minimum, I hope we’d learn of our shared value: we both value tested code. We might learn from each other more about the kinds of tests we like to write. Or how many tests we think are needed. Or how we rework existing tests. We might share some heuristics for deciding what next test to write or what isn’t worth testing. Through experimentation and reflection, we can grow and learn from each other.
- Previous: Testing, Testing...our Heuristics
- Next: Getting out of your ruts