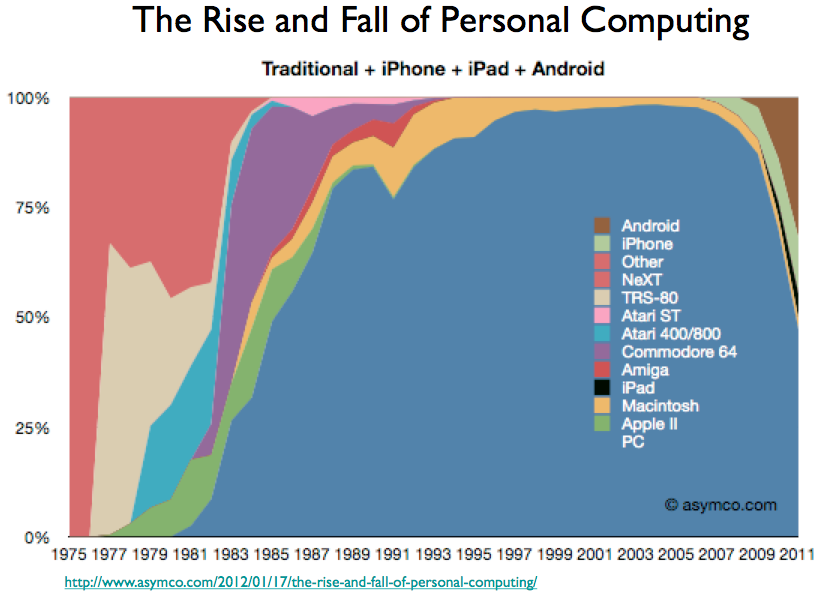
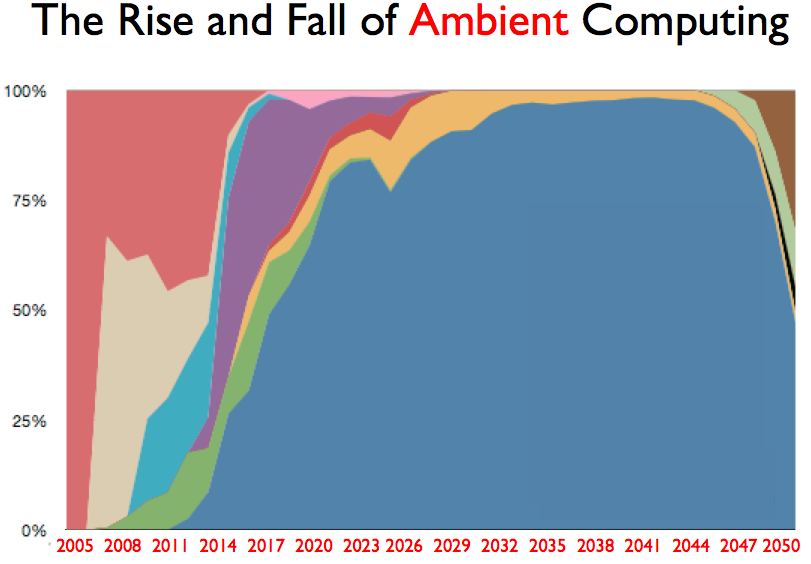
In 2011 I wrote a blog post where I present the big picture model I use for thinking about what some people were calling the “post-PC computing era”. Since then I’ve written other related posts, given talks, and had conversations with many people. Time appears to be validating my model so it seems like a good time to do an updated version of the original post.
There seems to be broad agreement that the Personal Computing Era has ended. But what does that really mean? What happens when one era ends and another begins? What is a “computing era”?
|
e·ra /ˈirə,ˈerə/
|
google.com
|
|
noun
|
- a long and distinct period of history with a particular feature or characteristic.
|
Digital computing emerged in the years immediately following World War II and by the early 1950s computers started to be commercially available. So, the first era of computing must have started about 1950. But how many other eras have passed since then? There are many ways that people slice up the history of modern computing. By the late 1960s the electronics foundation of computers had reached it “3rd generation” (vacuum tubes, transistors, integrated circuits). Some people consider that the emergence of software technologies such time-sharing, relational databases, or the web correspond to distinct eras.
I don’t think any of those ways of slicing up computing history represent periods that are long enough or distinctive enough to match the dictionary definition of “era” given above. I think we’ve only passed through two computing eras and have just recently entered the third. This picture summarizes my perspective:
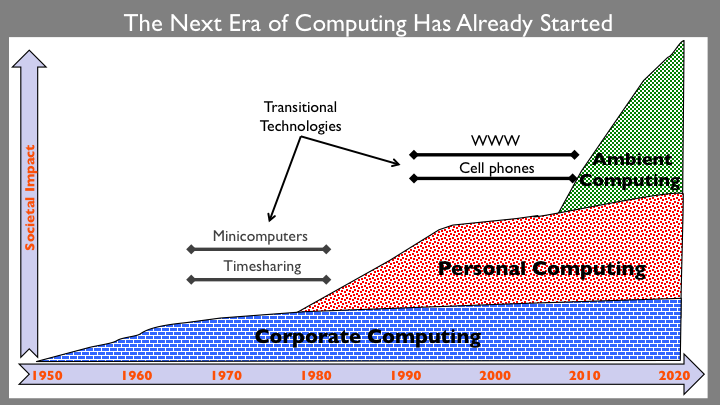
The must important idea from this picture is that, in my view, there have only been three major “eras” of computing. Each of these eras span thirty or more years and represents a major difference in the primary role computers play in human life and society. The three eras also correspond to major shifts in the dominant form of computing devices and software. What is pictured is a conceptual timeline, not a graph of any actual data. The y-axis is intended to represent something like overall impact of computing upon average individuals but can also be seen as an abstraction of other relevant factors such as the socioeconomic impact of computing technologies.
The first era was the Corporate Computing Era. It was focused on using computers to enhance and empower large organizations such as commercial enterprises and governments. Its applications were largely about collecting and processing large amounts of schematized data. Databases and transaction processing were key technologies.
During this era, if you “used a computer” it would have been in the context of such an organization. However, the concept of “using a computer” is anachronistic to that era. Very few individual had any direct contact with computing and for most of those that did, the contact was only via corporate information systems that supported some aspects of their jobs.
The Corporate Computing Era started with the earliest days of computing in the 1950’s and obviously corporate computing still is and will continue to be an important sector of computing. This is an important aspect of my model of computing eras. When a new era emerges, the computing applications and technologies of the previous eras don’t disappear. They continue and probably even grow. However, the overall societal impact of those previous forms of computing become relatively small in comparison of the scope of impact of computing in the new era.
Around 1980 the primary focus of computing started to rapidly shift away from corporate computing. This was the beginning of the Personal Computing Era. The Personal Computing Era was about using computers to enhance and empower individuals. Its applications were largely task-centric and focused on enabling individuals to create, display, manipulate, and communicate relatively unstructured information. Software applications such as word processors, spreadsheets, graphic editors, email, games, and web browsers were key technologies.
We are currently still in the early days of the third era. A change to the dominant from of computing is occurring that will be at least a dramatic as the transition from the Corporate Computing Era to the Personal Computing Era. This new era of computing is about using computers to augment the environment within which humans live and work. It is an era of smart devices, perpetual connectivity, ubiquitous information access, and computer augmented human intelligence.
We still don’t yet have a universally accepted name for this new era. Some common names are post-PC, pervasive, or ubiquitous computing. Others focus on specific technical aspects of the new era and call it cloud, mobile, or web computing. But none of these terms seem to capture the breadth and essence of the new era. They are either too focused on a specific technology or on something that is happening today rather than something that characterizes a thirty year span of time. The name that I prefer and which seems to be gaining some traction is “ambient computing”,
|
am·bi·ent /am-bee-uh nt/
|
dictionary.com
|
|
adjective
|
- of the surrounding area or environment
- completely surrounding; encompassing
|
In the Ambient Computing Era humans live in a rich environment of communicating computer enhanced devices interoperating with a ubiquitous cloud of computer mediated information and services. We don’t even perceive most of the computers we interact with. They are an invisible part of our everyday things and activities. In the Ambient Computing Era we still have corporate computing and task-oriented personal computing style applications. But the defining characteristic of this era is the fact that computing is shaping the actual environment within which we live and work.
The early years of a new era are an exciting time to be involved in computing. We all have our immediate goals and the much of the excitement and opportunity is focused on shorter term objectives. But while we work to create the next great app, machine learning model, smart IoT device, or commercially successful site or service we should occasionally step back and think about something bigger: What sort of ambient computing environment do we want to live within and is our current work helping or hindering its emergence?